[AWS] DynamoDB의 Auto Scaling 사용 시 Spike(갑작스러운 요청 증가)에 대해 Throttling이 발생한 사례
DynamoDB Throttling 발생 사례 정리
환경
- AWS
- DynamoDB
배경
- DynamoDB 프로비저닝된 모드에서 Auto Scaling 사용 시 Throttling이 발생해서 이유를 조사해서 정리함.
이슈
- DynamoDB 프로비저닝된 모드에서 Auto Scaling 설정을 사용했음에도 Throttling이 발생함.
이유
DynamoDB 관련 개념과 용어 정리
- 내용을 정리하기 앞서서 몇 가지 개념과 용어가 새로 나와서 정리한다.
온디맨드 모드와 프로비저닝된 모드
- 온디맨드 모드: 용량 계획 없이 초당 수백만 개의 요청을 처리할 수 있는 서버리스 청구 옵션으로 사용한만큼 지불하는 방식으로 보면 된다.
- 프로비저닝된 모드: 애플리케이션에 필요한 초당 읽기 및 쓰기 횟수를 지정할 수 있으며 Auto Scaling을 사용하여 트래픽 변경에 따라 테이블의 프로비저닝된 용량을 자동으로 조정할 수 있다.
- 관련 링크: https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/capacity-mode.html
WCU와 RCU
- 프로비저닝된 용량 모드에서 애플리케이션에 필요한 초당 데이터 읽기 및 쓰기 단위이다.
- WCU: 테이블에서 데이터를 쓰는 각 API 호출이 쓰기 요청이다.
- RCU: 테이블에서 데이터를 읽는 각 API 호출이 읽기 요청이다.
- 각 WCU 및 RCU에 대한 용량은 공식 문서에 나와있다.
- 관련 링크: https://aws.amazon.com/ko/dynamodb/pricing/provisioned/
Auto Scaling
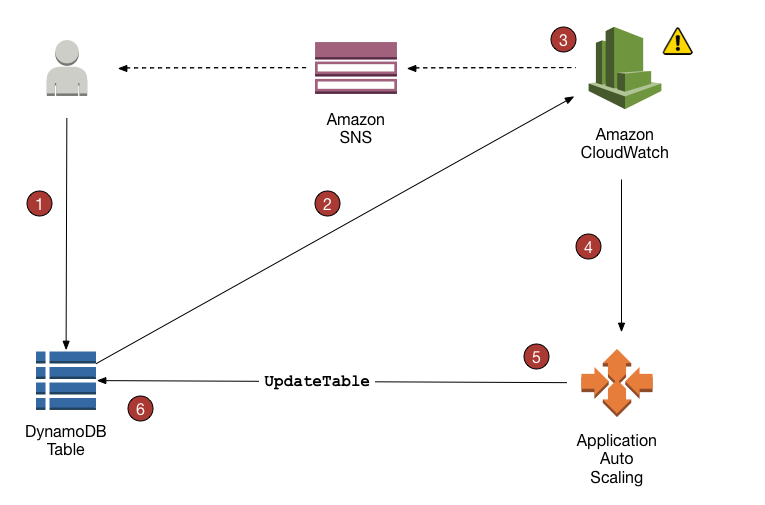
- 위에 설명한 용량 단위의 최솟값 및 최댓값 그리고 목표 사용률 설정할 수 있다.
- 목표 사용률에 따라 최솟값 및 최댓값 사이에서 용량을 조절한다. 간단하게 예를 들어 목표 사용률이 70% 이고 700 RCU를 사용한다면 1000 RCU를 프로비저닝 해둔다. 아래 정리하겠지만 남은 300 RCU를 패딩(Padding)이라 한다.
- 관련 링크: https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/AutoScaling.html
패딩(Padding), 버스트 용량 그리고 Spike
- 패딩(Padding): 목표 사용률만큼을 제외한 읽기 쓰기 용량 단위를 말한다.
- 버스트 용량: “사용 가능한 처리량을 완전히 사용하지 않을 때마다 DynamoDB는 나중에 사용량 급증을 처리하기 위해 처리량 버스트에 사용하지 않은 용량 일부를 예약해 둡니다.”라고 공식 문서에 나와있다.
- Spike: 갑작스러운 데이터 요청을 의미한다.
- 관련 링크: https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/burst-adaptive-capacity.html
- 관련 링크: https://aws.amazon.com/ko/blogs/database/handle-traffic-spikes-with-amazon-dynamodb-provisioned-capacity/
Spike 발생 시 Throttling 발생 이유
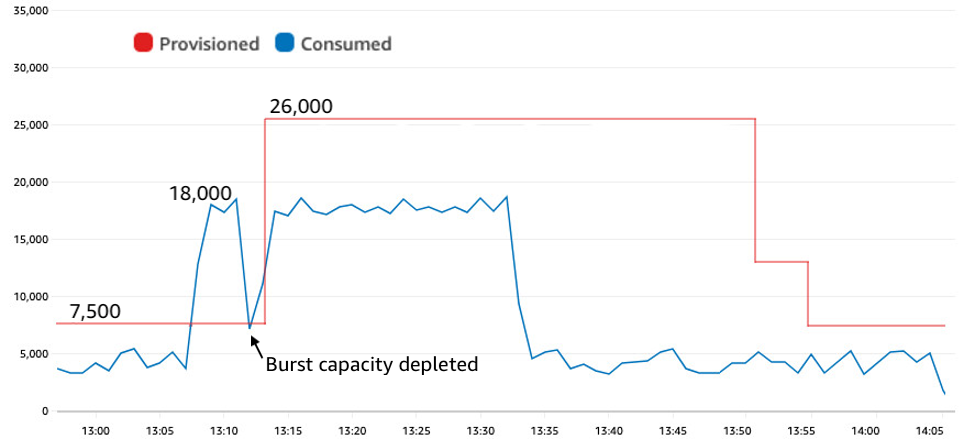

- 프로비저닝된 용량을 훨씬 넘어서는 Spike(갑작스러운 데이터 요청) 발생 시 아래와 같은 순서로 요청이 처리될 수 있다고 한다.
목표 사용률 이하 RCU 사용
-> 모든 RCU(목표 사용률 이하 RCU + Padding)를 통해 처리
-> 버스트 용량에서 처리
- Spike에 대해 그래프에서와 같이 처음에는 버스트 용량에서 처리되다가 버스트 용량을 다 소진하면서 Throttling이 발생한다. 이후 Auto Scaling이 완료된 이후에는 Throttling이 사라진다.
- 문서에 따르면 “Auto scaling triggers when your consumed capacity breaches the configured target utilization for two consecutive minutes. CloudWatch alarms might have a short delay of up to a few minutes before triggering auto scaling.”라고 나와있다.
- DynamoDB의 경우 Auto Scaling이 일어나려면 CloudWatch에 1분간 연속해서 사용된 값이 목표 사용률을 넘어야 한다고 했다. 그렇기에 아래와 같은 이유로 지연이 생기게 되며 이게 순간적인 많은 요청에 대해 Throttling을 발생 시킨다.
- CloudWatch에 표시되려면 약간의 시간 지연이 필요하다.
- CloudWatch에 연속된 1분동안 목표 사용률을 넘는 상황이 발생하면 Auto Scaling을 시작한다.
- Auto Scaling이 되는 과정에서 위에서 언급한 “목표 사용률 이하 RCU 사용 → 모든 RCU(목표 사용률 이하 RCU + Padding)를 통해 처리 → 버스트 용량에서 처리”를 넘어서는 요청에 대해서는 Throttling이 발생한다.
- 관련 링크: https://aws.amazon.com/ko/blogs/database/handle-traffic-spikes-with-amazon-dynamodb-provisioned-capacity/
- 관련 링크: https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/AutoScaling.html
작가의 생각
- Auto Scaling에서도 급격한 요청에 대해서는 Scaling을 탐지하는 부분과 조정하는 시간이 필요하기에 앞으로 설계시 이에 대한 고려도 하면 좋을거 같다.
- 관련 조사를 진행하면서 DynamoDB Auto Scaling에 대해 많이 배웠다.
- 예상하지 못한 급격한 트래픽 요청에 대해서는 알람이 오게 해야하며 트랙픽 증가가 예정된 부분이 있다면 점검하는 습관을 만들어야겠다.
참고자료
- https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/capacity-mode.html
- https://aws.amazon.com/ko/dynamodb/pricing/provisioned/
- https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/AutoScaling.html
- https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/burst-adaptive-capacity.html
- https://aws.amazon.com/ko/blogs/database/handle-traffic-spikes-with-amazon-dynamodb-provisioned-capacity/