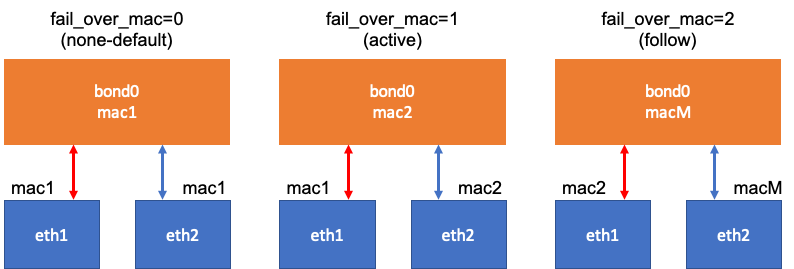
Make network bonding and test if it is still work even though active slave is down.
Environment and Prerequisite
- CentOS 7.7.1908
- Ubuntu 18.04
- VirtualBox
- Bash shell(/bin/bash)
Basic Network Structure
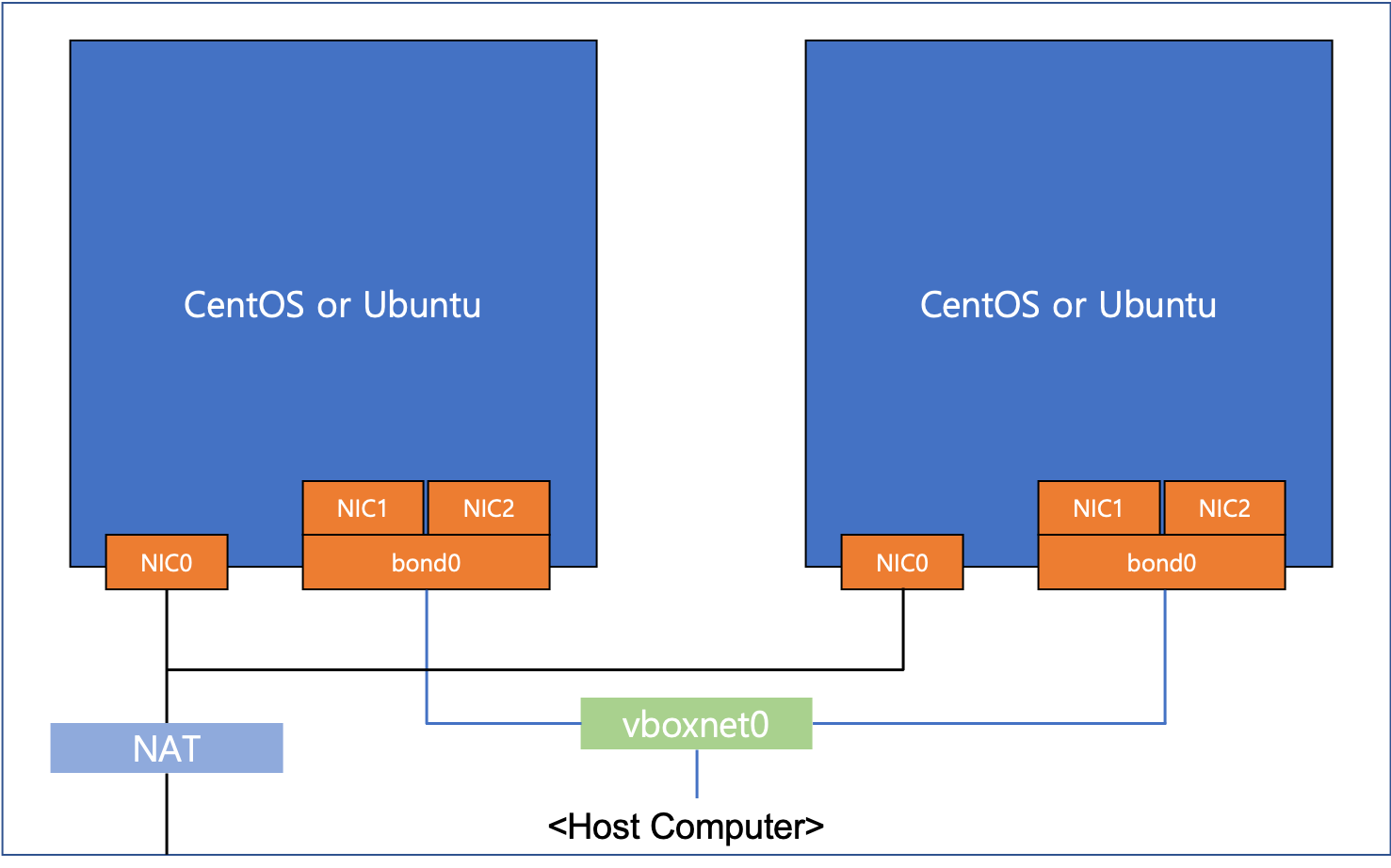
- Bond two NICs
- By using Host-only Adapter, each VM’s two NICs are connected to vboxnet0
- In VirtualBox Settings-Network, Adapter 1 is connected to default NAT.
- In VirtualBox Settings-Network, add new two adapters Adapter 2 and Adapter 3.
Scenario
- Ping to bonding interface’s IP address from Client to Server.
- Make active slave to Down in Server.
- Check ping is still going well.
Network Bonding Setting
CentOS
centos-client
- bond0
- /etc/sysconfig/network-scripts/ifcfg-bond0
TYPE=Bond
BOOTPROTO=static
DEFROUTE=no
NAME=bond0
DEVICE=bond0
ONBOOT=yes
PREFIX=24
IPADDR=192.168.99.101
BONDING_OPTS="mode=1 miimon=100 fail_over_mac=1"
- enp0s8
- /etc/sysconfig/network-scripts/ifcfg-enp0s8
NAME=enp0s8
DEVICE=enp0s8
TYPE=Ethernet
BOOTPROTO=none
ONBOOT=yes
MASTER=bond0
SLAVE=yes
- enp0s9
- /etc/sysconfig/network-scripts/ifcfg-enp0s9
NAME=enp0s9
DEVICE=enp0s9
TYPE=Ethernet
BOOTPROTO=none
ONBOOT=yes
MASTER=bond0
SLAVE=yes
centos-server
- bond0
- /etc/sysconfig/network-scripts/ifcfg-bond0
TYPE=Bond
BOOTPROTO=static
DEFROUTE=no
NAME=bond0
DEVICE=bond0
ONBOOT=yes
PREFIX=24
IPADDR=192.168.99.102
BONDING_OPTS="mode=1 miimon=100 fail_over_mac=1"
- enp0s8
- /etc/sysconfig/network-scripts/ifcfg-enp0s9
NAME=enp0s8
DEVICE=enp0s8
TYPE=Ethernet
BOOTPROTO=none
ONBOOT=yes
MASTER=bond0
SLAVE=yes
- enp0s9
- /etc/sysconfig/network-scripts/ifcfg-enp0s9
NAME=enp0s9
DEVICE=enp0s9
TYPE=Ethernet
BOOTPROTO=none
ONBOOT=yes
MASTER=bond0
SLAVE=yes
Ubuntu
- 18.04 use netplan to set network.
- Make yaml file and apply it using
sudo netplan applycommand
ubuntu-client
- /etc/netplan/50-cloud-init.yaml
# This file is generated from information provided by
# the datasource. Changes to it will not persist across an instance.
# To disable cloud-init's network configuration capabilities, write a file
# /etc/cloud/cloud.cfg.d/99-disable-network-config.cfg with the following:
# network: {config: disabled}
network:
ethernets:
enp0s3:
dhcp4: true
enp0s8:
dhcp4: false
enp0s9:
dhcp4: false
version: 2
bonds:
bond0:
dhcp4: false
addresses:
- 192.168.225.101/24
gateway4: 192.168.225.1
interfaces:
- enp0s8
- enp0s9
parameters:
mode: active-backup
primary: enp0s8
fail-over-mac-policy: active
mii-monitor-interval: 100
ubuntu-server
- /etc/netplan/50-cloud-init.yaml
# This file is generated from information provided by
# the datasource. Changes to it will not persist across an instance.
# To disable cloud-init's network configuration capabilities, write a file
# /etc/cloud/cloud.cfg.d/99-disable-network-config.cfg with the following:
# network: {config: disabled}
network:
ethernets:
enp0s3:
dhcp4: true
enp0s8:
dhcp4: false
enp0s9:
dhcp4: false
version: 2
bonds:
bond0:
dhcp4: false
addresses:
- 192.168.225.102/24
gateway4: 192.168.225.1
interfaces:
- enp0s8
- enp0s9
parameters:
mode: active-backup
primary: enp0s8
fail-over-mac-policy: active
mii-monitor-interval: 100
Test
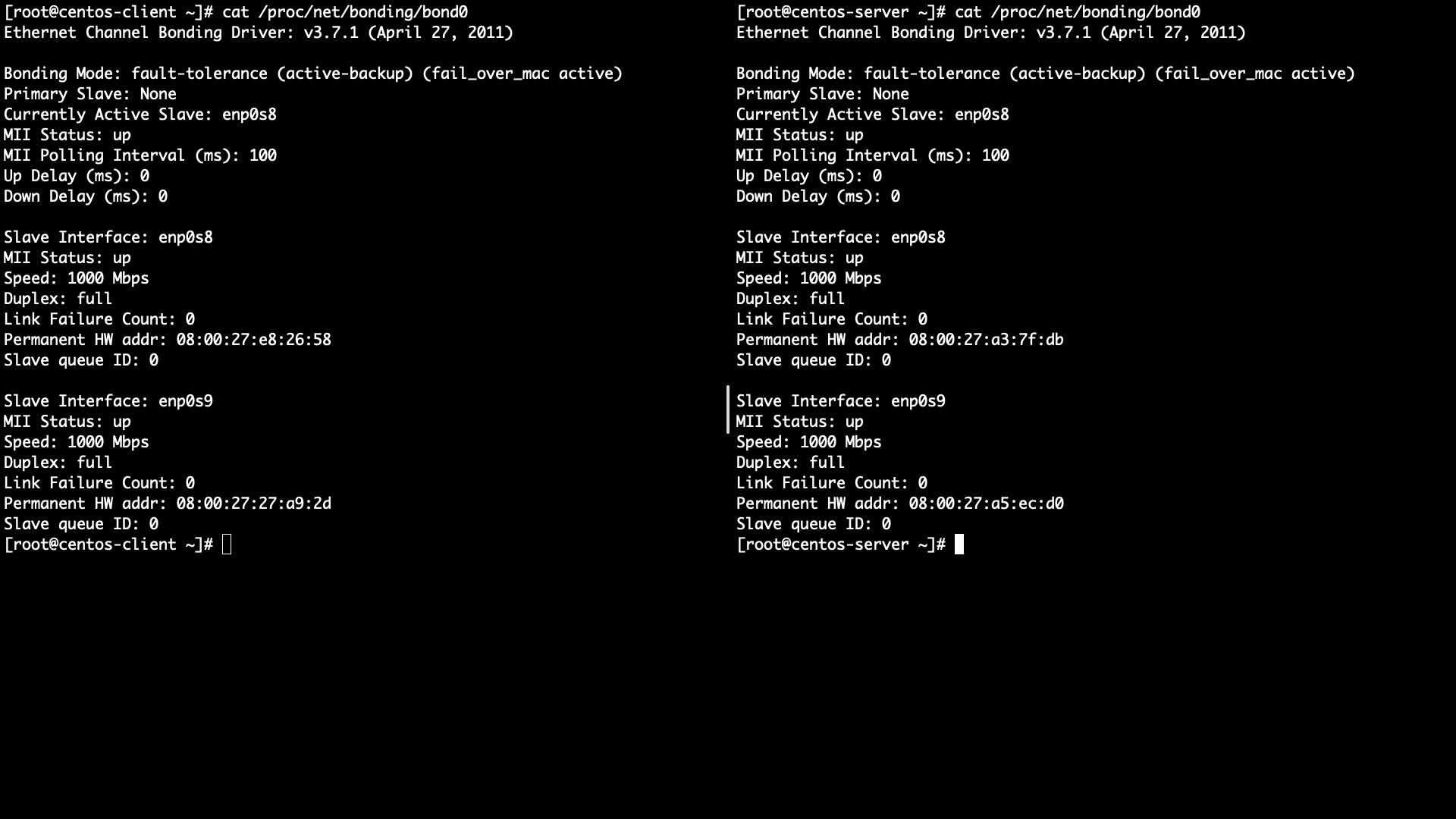
Check each active slave
- Command:
cat /proc/net/bonding/bond0 - Left is Client and right is Server
- Active slave: enp0s8
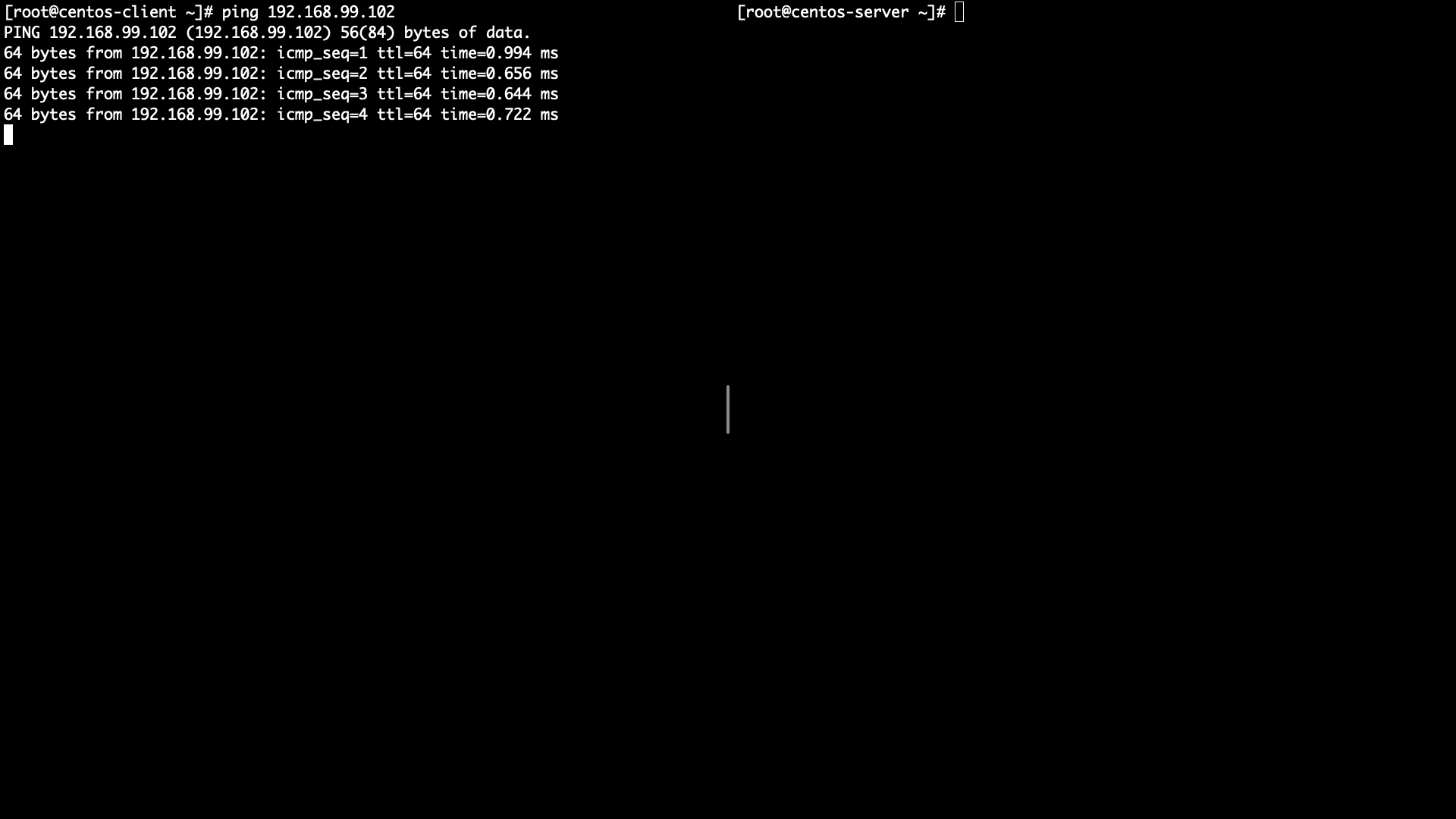
Start ping Client -> Server
Server active slave link down
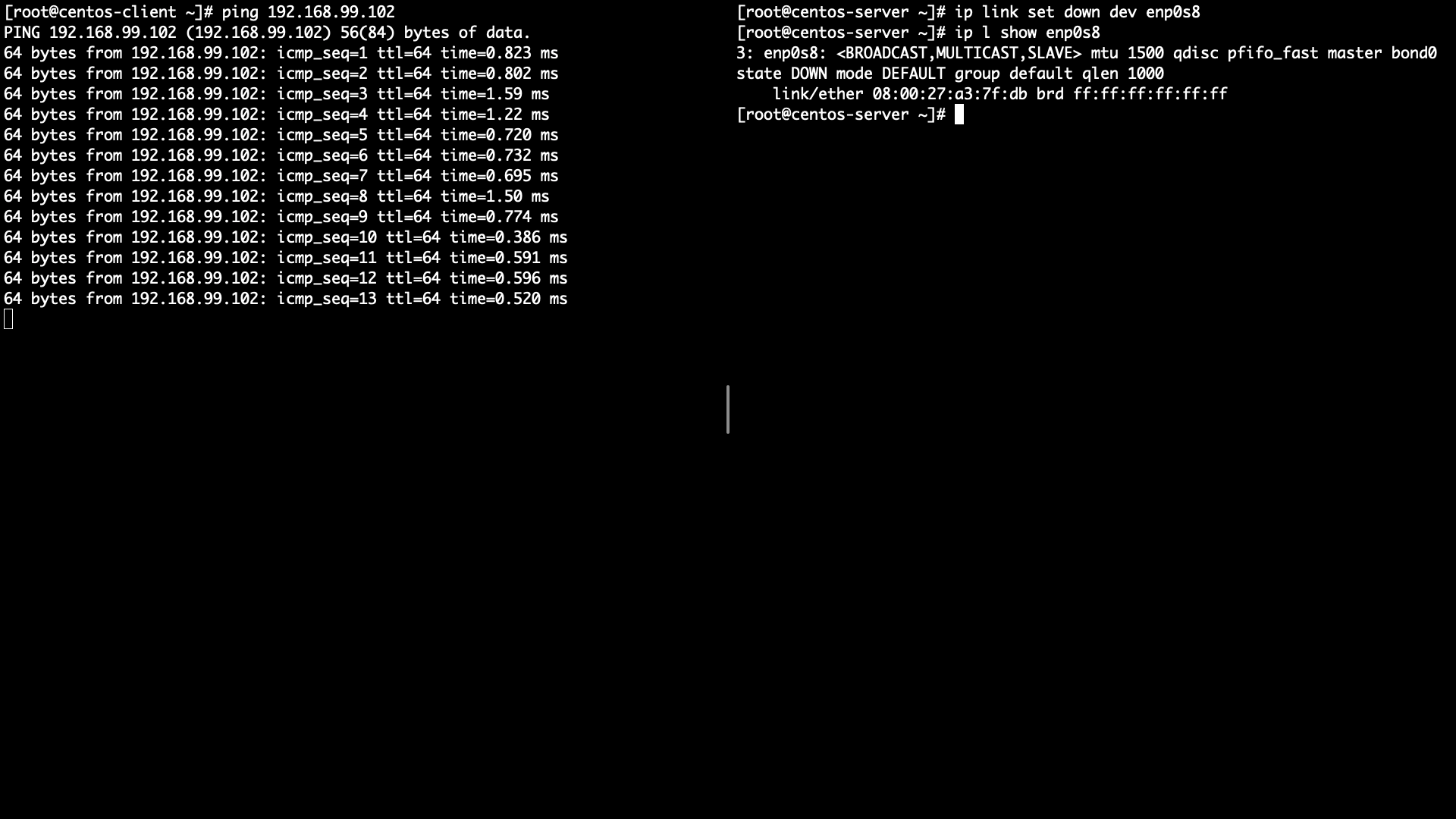
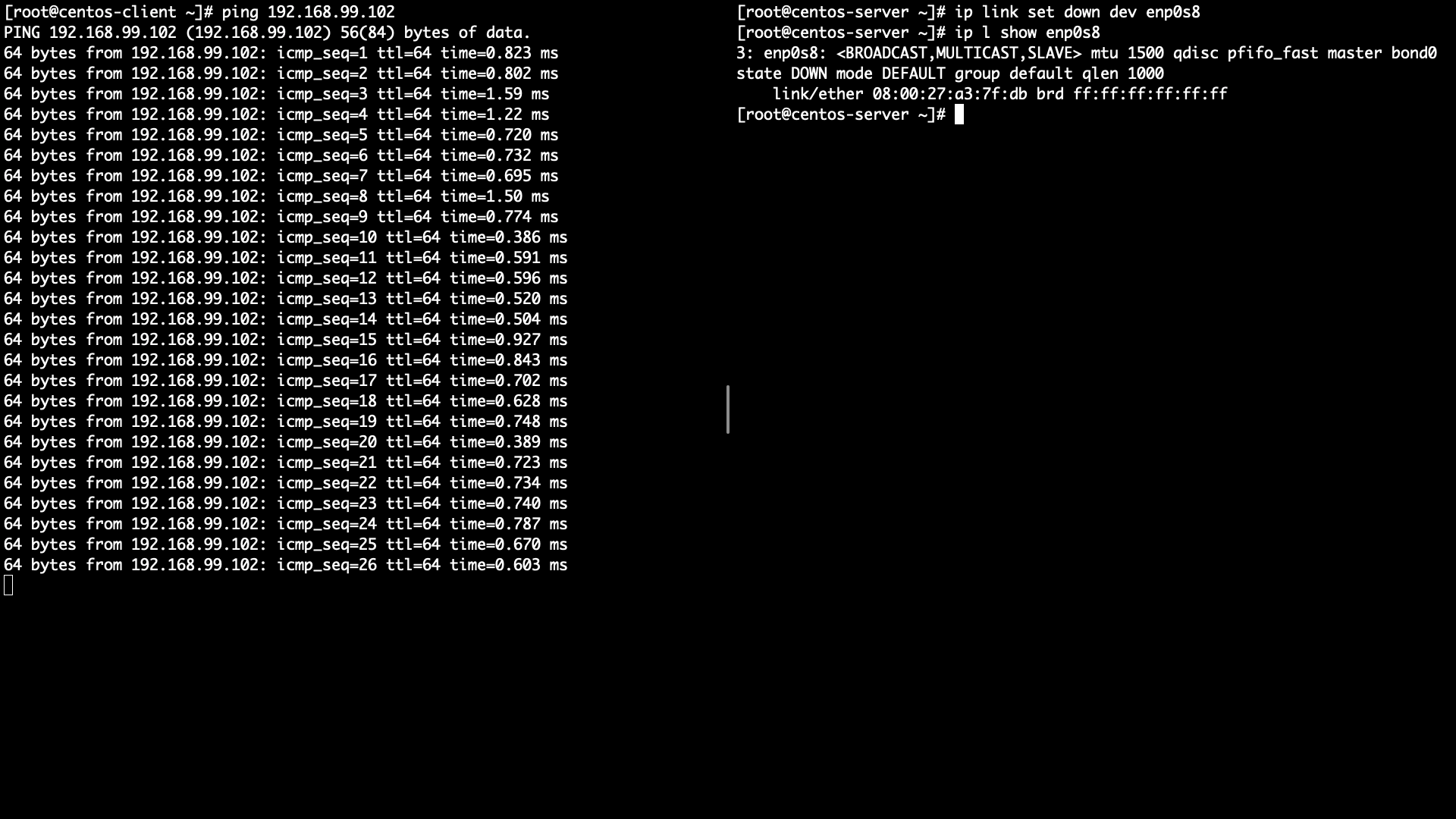
Check ping is going well
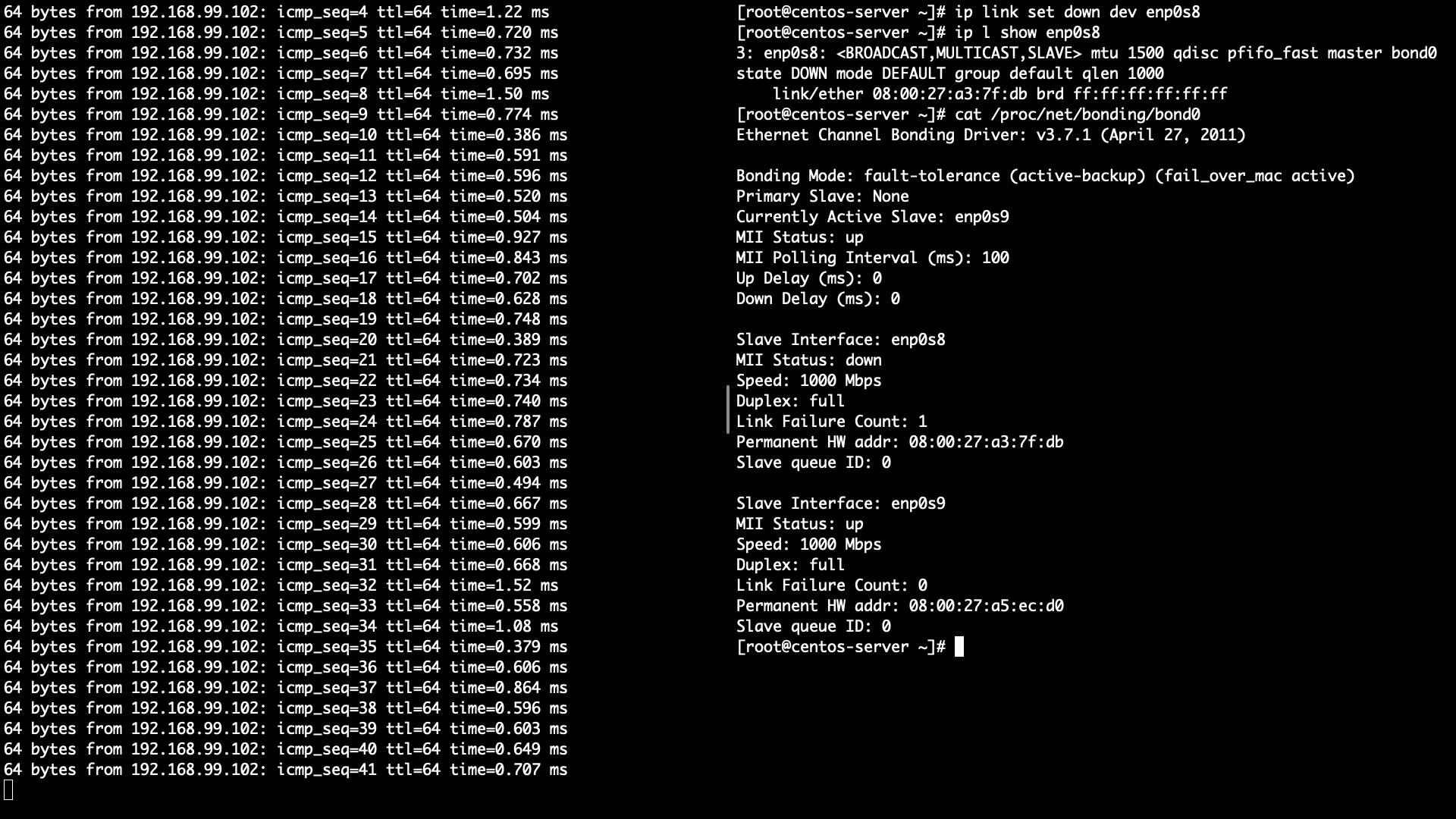
Check which one is active slave in Server
- enp0s8 -> enp0s9
Reference
- https://www.interserver.net/tips/kb/network-bonding-types-network-bonding/
- https://askubuntu.com/questions/1033531/how-can-i-create-a-bond-interface-in-ubuntu-18-04
- https://www.snel.com/support/how-to-set-up-lacp-bonding-on-ubuntu-18-04-with-netplan/
- https://netplan.io/examples
- https://netplan.io/reference