Linux 기반 운영체제나 Mac OS에서 파일을 16진수나 2진수 형태로 볼 수 있는 xxd 명령어의 사용법과 예제를 보자
환경 및 선수조건
- Linux
- Mac OS
xxd
-
xxd: 주어진 파일이나 standart input으로 들어온 문자들에 대해서hex dump(컴퓨터 데이터의 16진법적인 보임새)를 만들어 준다. Endian에 관계 없이 파일에 존재하는 순서대로 나옵니다. -
기본 사용법:
xxd [file name]
xxd의 예제와 옵션
기본 파일 생성
- 아래와 같이
test.txt라는 UTF-8 형식의 파일을 만들고 예제를 보여드리겠습니다. 파일의 내용도 아래에 첨부합니다. test.txt링크: https://gist.github.com/c3af533139621a58f3f9051e6a09bc6f.gitfile명령어 다음에 파일명을 입력하면 파일의 형식에 대해서 간략하게 보여줍니다.
$ touch test.txt
$ vim test.txt
... # 텍스트들 입력 후
$ file test.txt
test.txt: UTF-8 Unicode text, with very long lines
기본 사용법 및 예제
xxd [파일명]
$ xxd test.txt
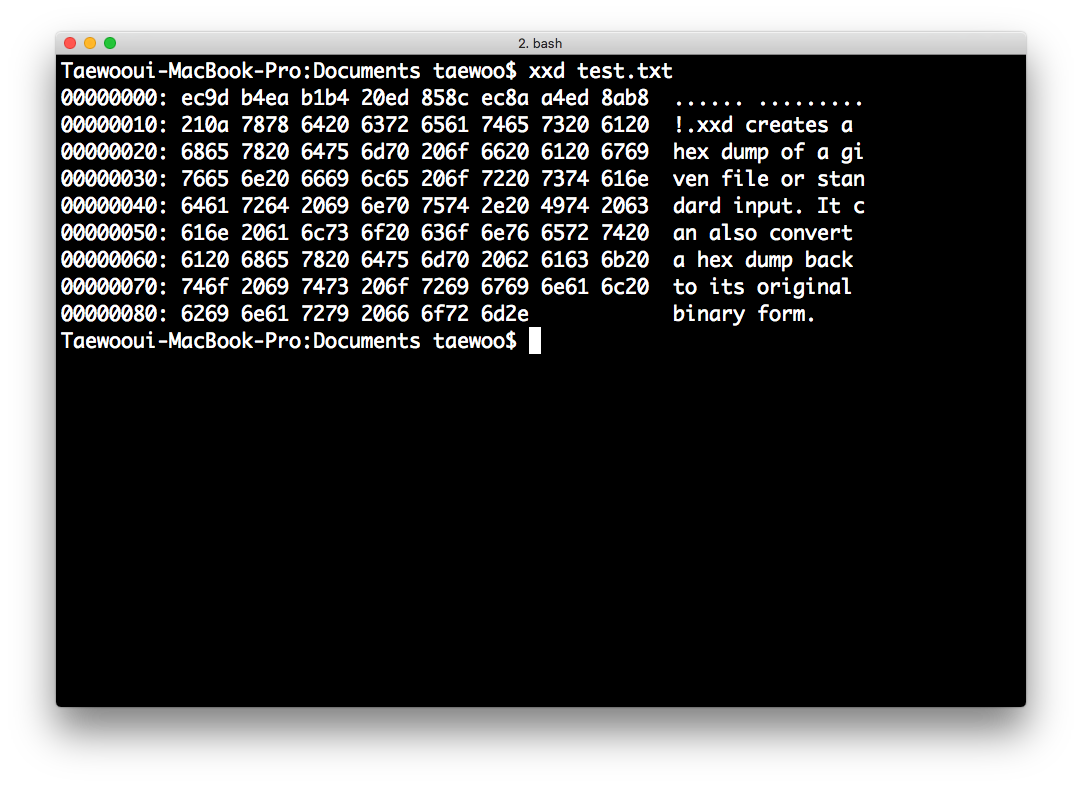
- 제일 좌측에 파일의 상대주소가 나옵니다.
- 기본적으로 2바이트씩 묶어서 보여줍니다.
- 기본적으로 1줄은 16바이트씩 나타납니다. 나중에 사용하는 옵션에 따라서 다르게 나오기도 합니다.
- 제일 우측에는 ASCII형태로 각 바이트의 값들을 보여줍니다.
옵션에 따른 사용법 및 예제
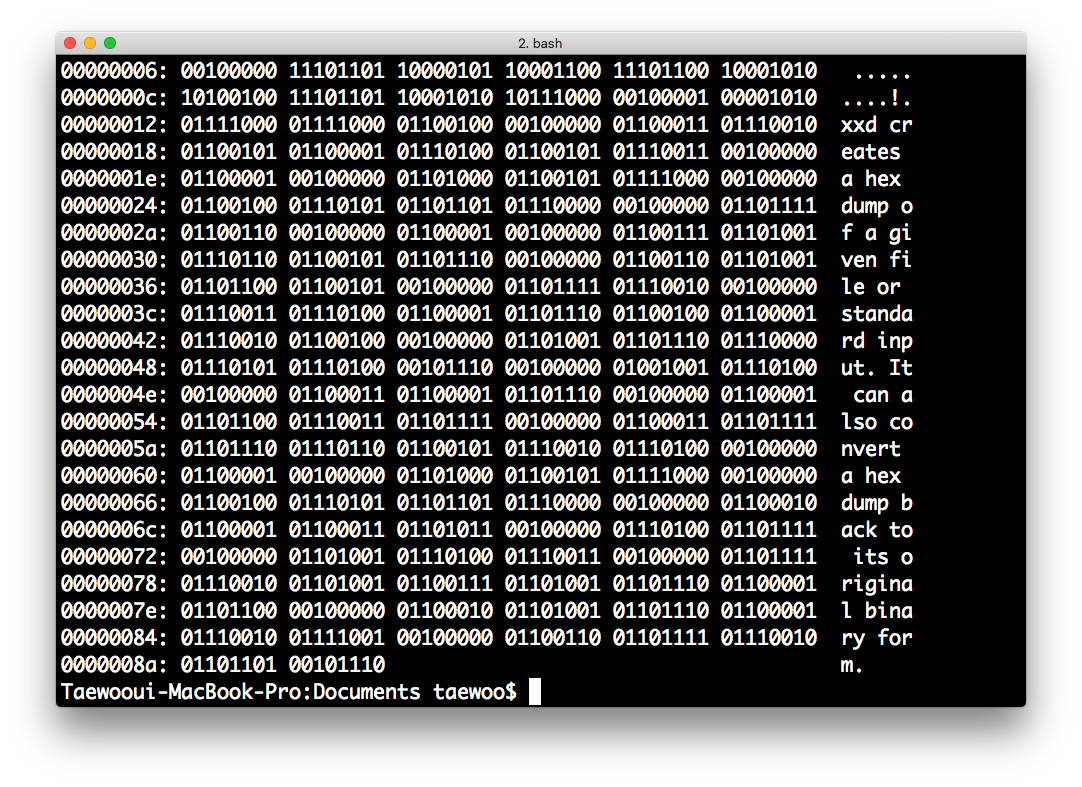
-b: bit로 표시해줍니다.
$ xxd -b test.txt
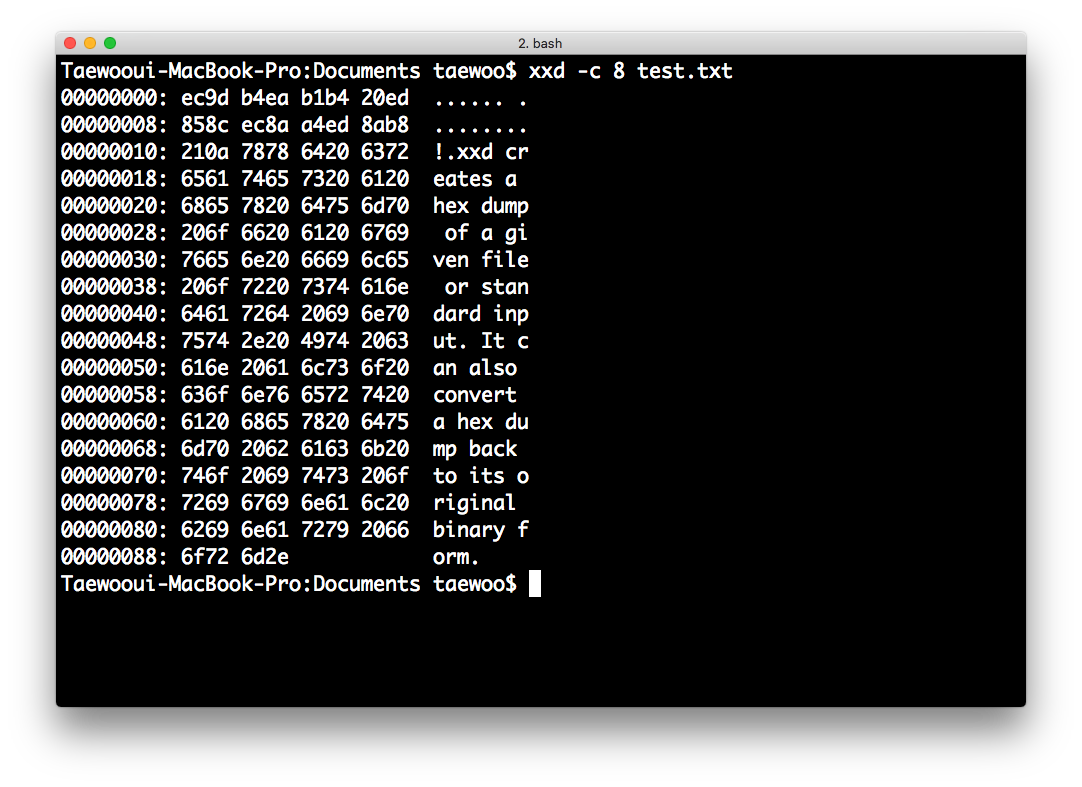
-c <cols>: 한 줄에 몇개의 바이트를 표현할지<cols>값으로 정합니다.
$ xxd -c 8 test.txt
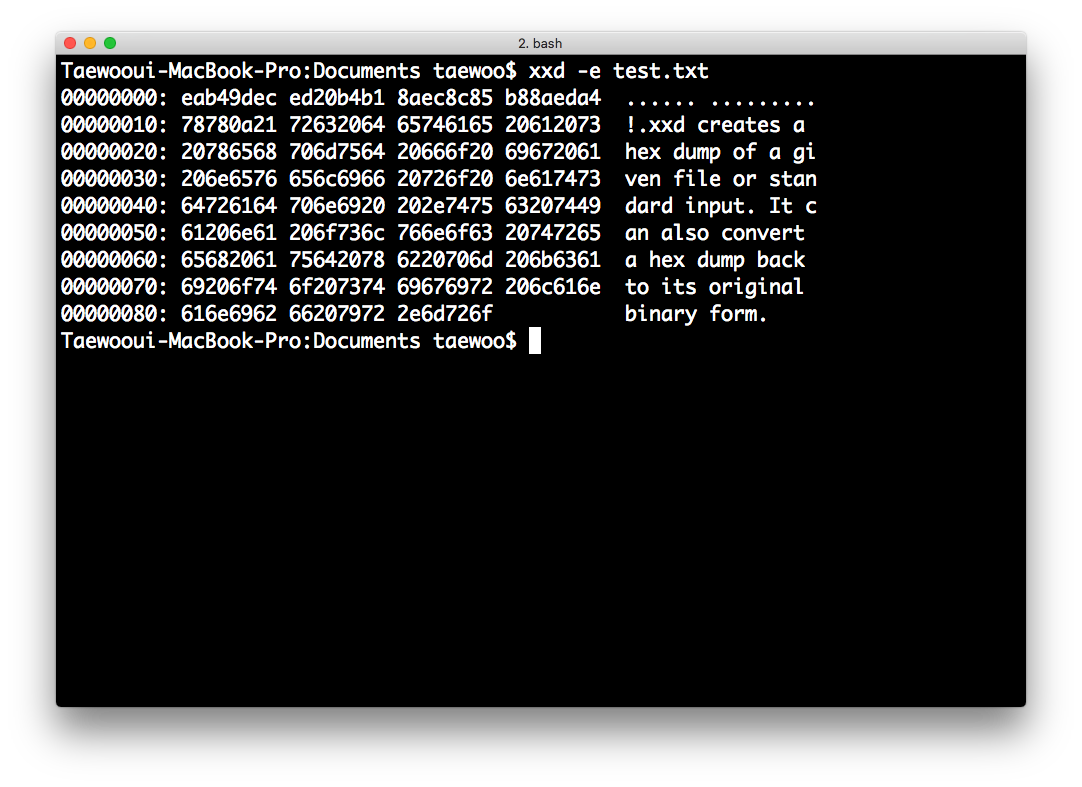
-e: 우측에 나타나는 값들이 ASCII가 아닌 EBCDIC로 합니다.
$ xxd -e test.txt
-g <bytes>:<bytes>에 들어가는 값만큼 묶어서 표현하며 기본 값은 2입니다.
$ xxd -e test.txt
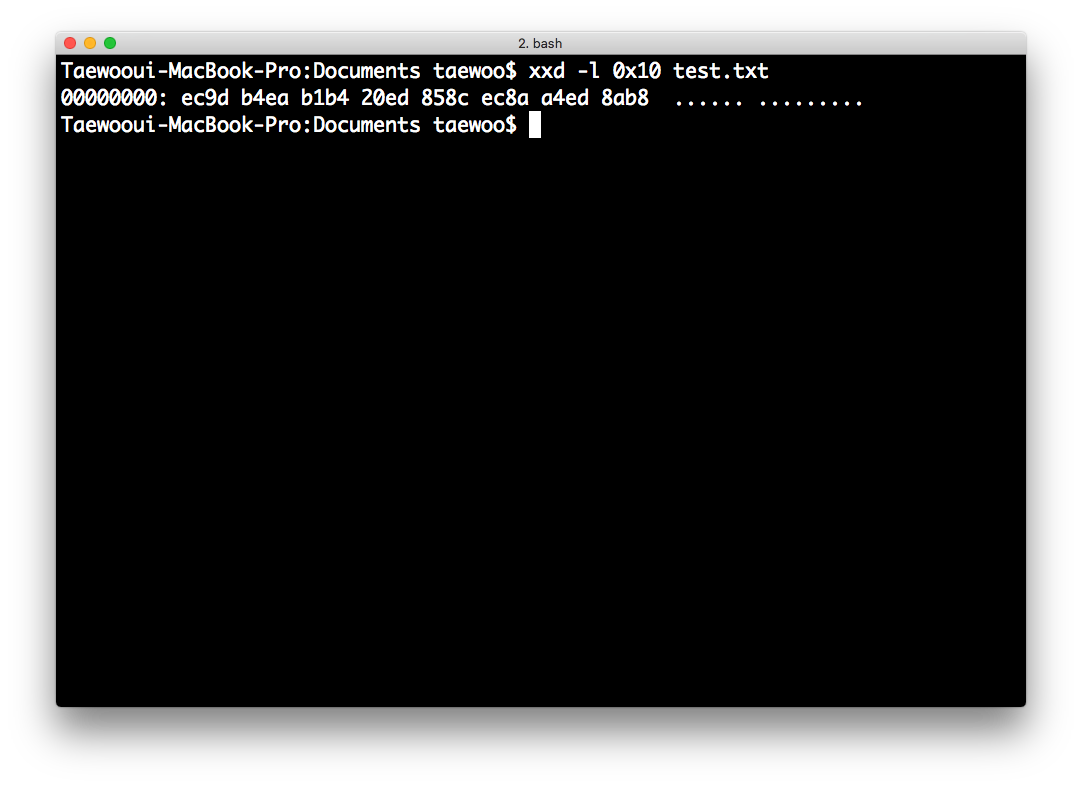
-l <value>:<value>만큼만 hexdump를 합니다.
$ xxd -l 0x10 test.txt
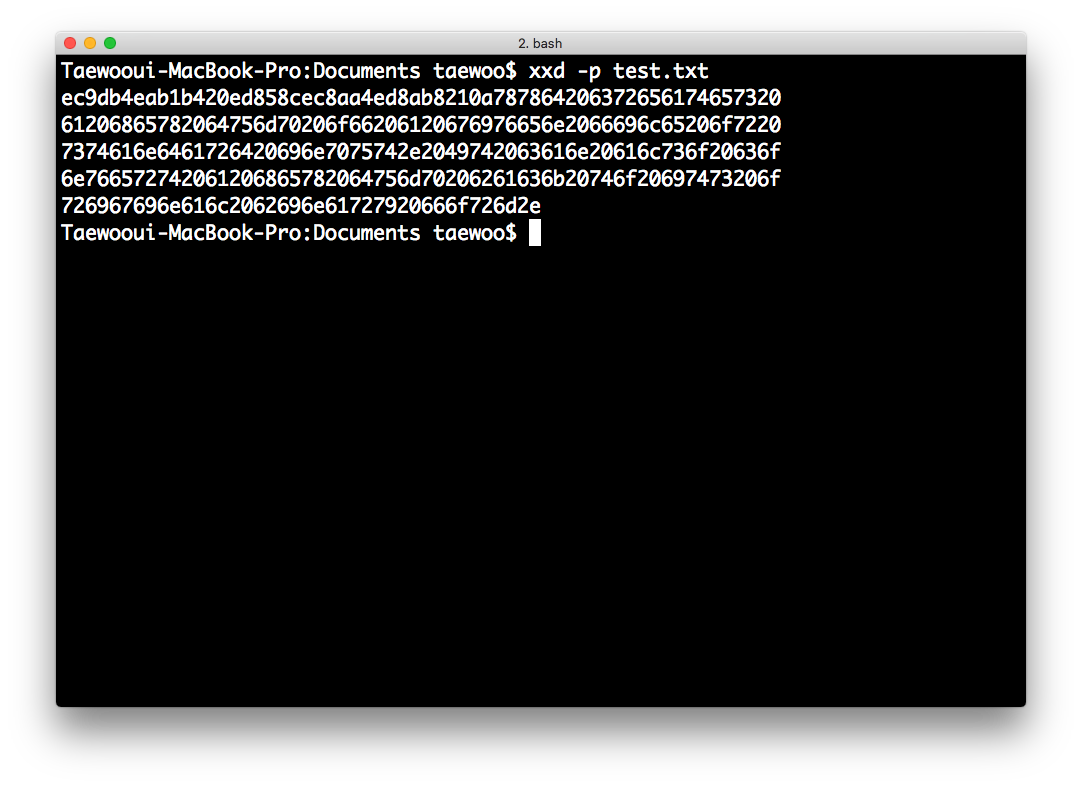
-p: 포맷이 없는 hexdump를 출력합니다.
$ xxd -p test.txt
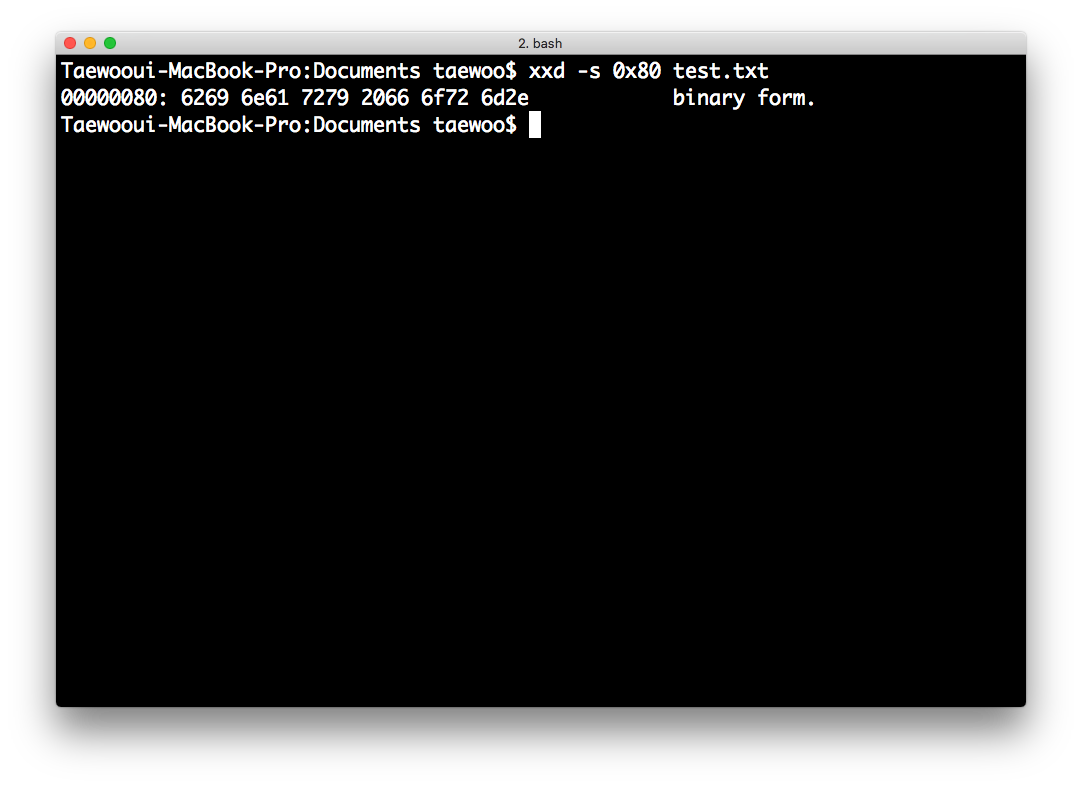
-s <offset>:<offset>의 위치부터 hexdump를 보여줍니다.
$ xxd -s 0x80 test.txt
-u: byte를 대문자로 출력합니다.- 그 외에
-r와-seek <offset>가 있는데 각각-r은 hexdump를 binary로 바꾸는 명령어이며-seek <offset>는-r와 관련해서 파일 포지션을 정해주는 옵션입니다.