Environment and Prerequisite
- Java
- IntelliJ
Setting
Prepare Spring Test
- Make project like below in https://start.spring.io/
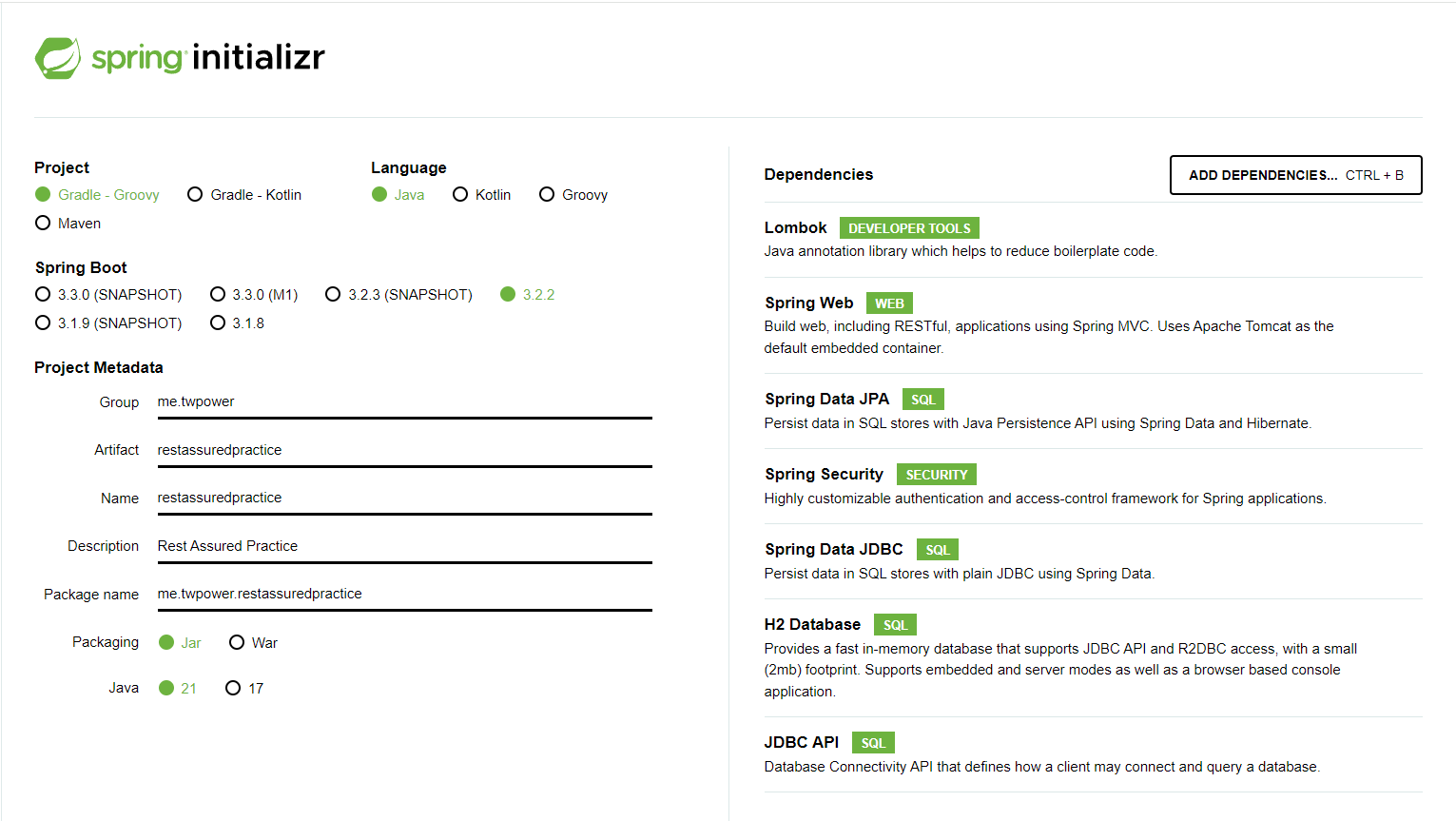
Setting Rest Assured in Gradle
plugins {
id 'java'
id 'org.springframework.boot' version '3.2.2'
id 'io.spring.dependency-management' version '1.1.4'
}
group = 'me.twpower'
version = '0.0.1-SNAPSHOT'
java {
sourceCompatibility = '21'
}
configurations {
compileOnly {
extendsFrom annotationProcessor
}
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jdbc'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
implementation 'org.springframework.boot:spring-boot-starter-security'
implementation 'org.springframework.boot:spring-boot-starter-web'
compileOnly 'org.projectlombok:lombok'
runtimeOnly 'com.h2database:h2'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'org.springframework.security:spring-security-test'
testImplementation 'io.rest-assured:rest-assured:5.4.0' // Added
}
tasks.named('test') {
useJUnitPlatform()
}
Code
given(): Set up necessary components such as headers or parameters before making a requestwhen(): Input URI or method for the actual requestthen(): Define verification steps- Add the usage methods for
header,pathParam,queryParam,body,logandextractbelow.
package me.twpower.restassuredpractice;
import io.restassured.RestAssured;
import io.restassured.response.ExtractableResponse;
import io.restassured.response.Response;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import static io.restassured.RestAssured.*;
import static org.hamcrest.Matchers.equalTo;
@SpringBootTest
public class RestAssuredPracticeTest {
@BeforeAll
static void beforeAll(){
// Setting BaseURI
RestAssured.baseURI = "http://echo.jsontest.com/";
}
@Test
void restAssuredPracticeTest() {
// JSON Example
// Request Method: GET
// Call http://echo.jsontest.com/key1/value1/key2/value2/key3/3?queryParameterKey=queryParameterValue
/*
{
"key1": "value1",
"key2": "value2",
"key3": "3"
}
*/
// given(): Start building the request part of the test io.restassured.specification.
// when(): Start building the DSL expression by sending a request without any parameters or headers etc.
// then(): Returns a validatable response that's lets you validate the response.
// given() and when() returns RequestSpecification object
ExtractableResponse<Response> extractableResponse = given().log().all().
header("Content-Type", "application/json"). // Specify the headers that'll be sent with the request.
pathParam("pathParameter", 3). // Specify a path parameter.
queryParam("queryParameterKey", "queryParameterValue"). // Specify a query parameter that'll be sent with the request.
//body(). // Specify request body.
when().
get("/key1/value1/key2/value2/key3/{pathParameter}").
then().
body("key1", equalTo("value1")).
extract();
Assertions.assertEquals(200, extractableResponse.statusCode());
Assertions.assertEquals("value1", extractableResponse.jsonPath().getString("key1"));
}
}
Result
- Success

- Fail
java.lang.AssertionError: 1 expectation failed.
JSON path key1 doesn't match.
Expected: value2
Actual: value1