Sequence Diagram
Environment and Prerequisite
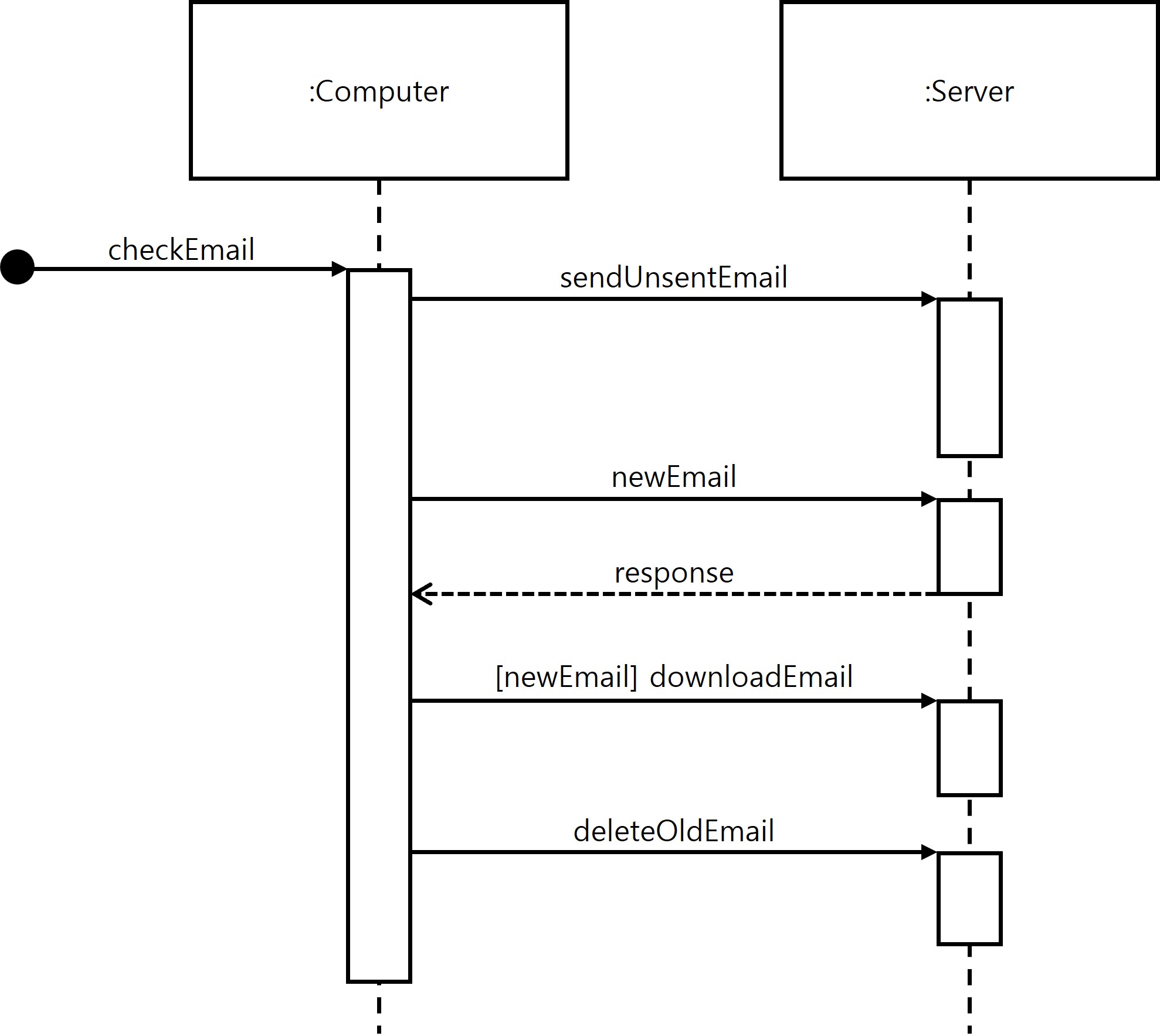
Sequence Diagram
Sequence Diagram
- Sequence Diagram: UML diagram which shows interactions between objects based on time sequence
Sequence Diagram Basic Notation
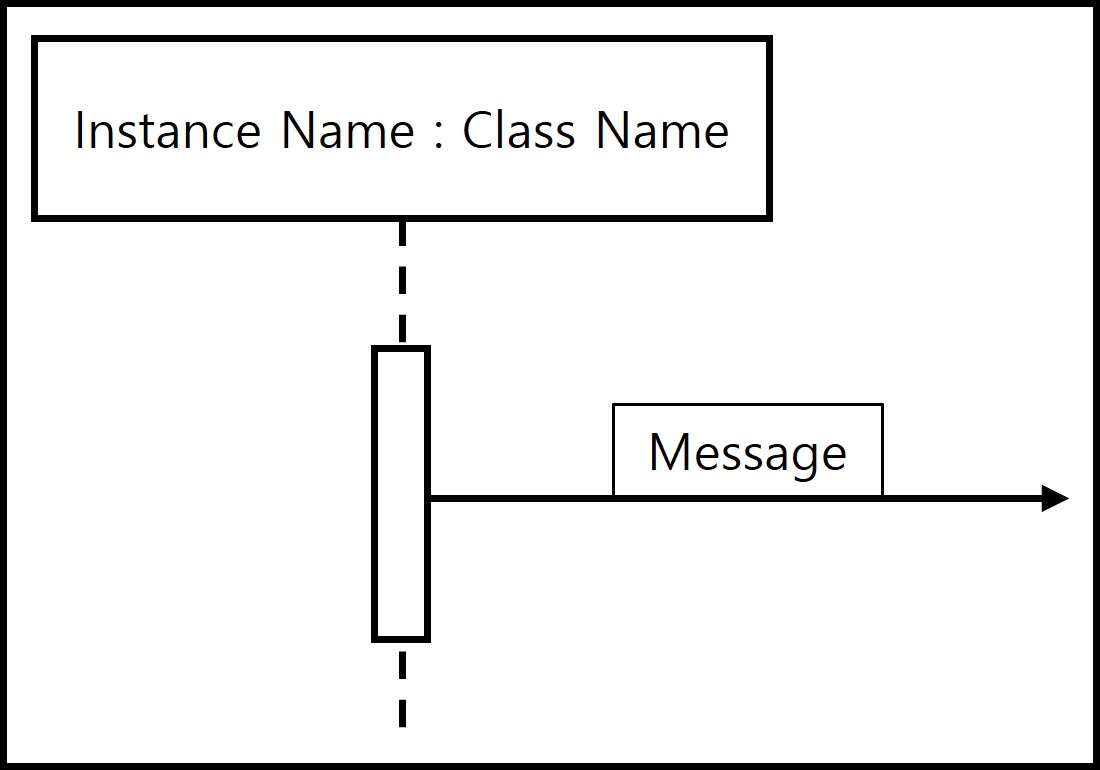
- Object: Interacting entities(objects or classes) in a sequence diagram which are placed at the top of the diagram, each having a lifeline represented by a vertical dashed line.
- Lifeline: A line shows object’s existence and interactions between objects through time. Time goes up to down. It is depicted as a rectangle when state is active.
- Message: It is an request and response in objects interactions which depicted as directed line.
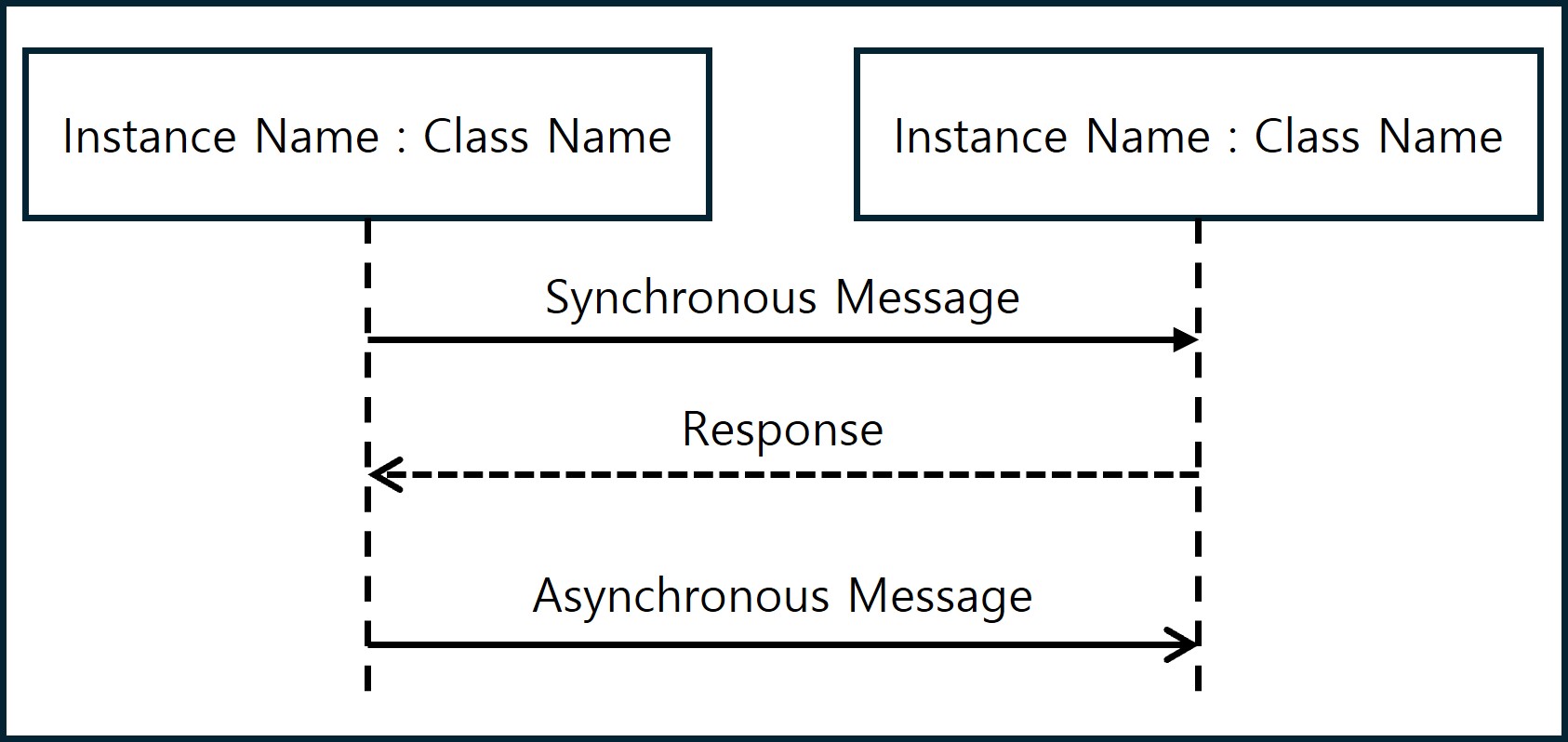
Message Type
- Synchronous Message: Sender waits until receive response message. It is depicted as an arrow as shown in the diagram below.
- Asynchronous Message: Sender continues execution without waiting for a response message. It is depicted as an arrow as shown in the diagram below.
- Response Message: It is depicted as shown below and can be omitted when unclear.
Combined Fragments
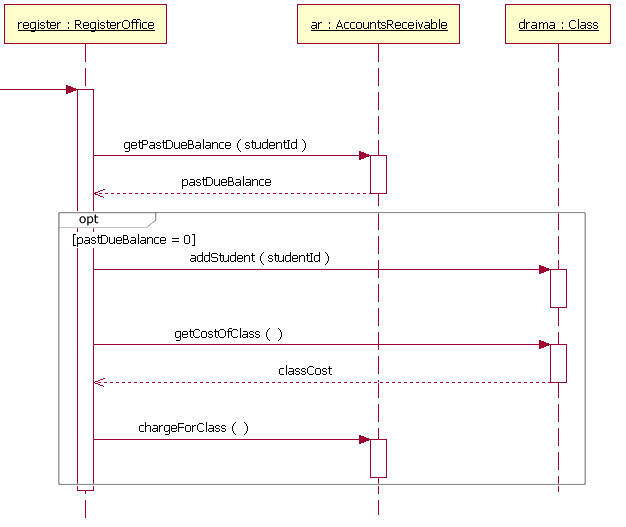
Guards
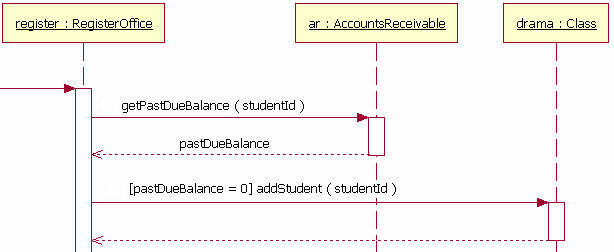
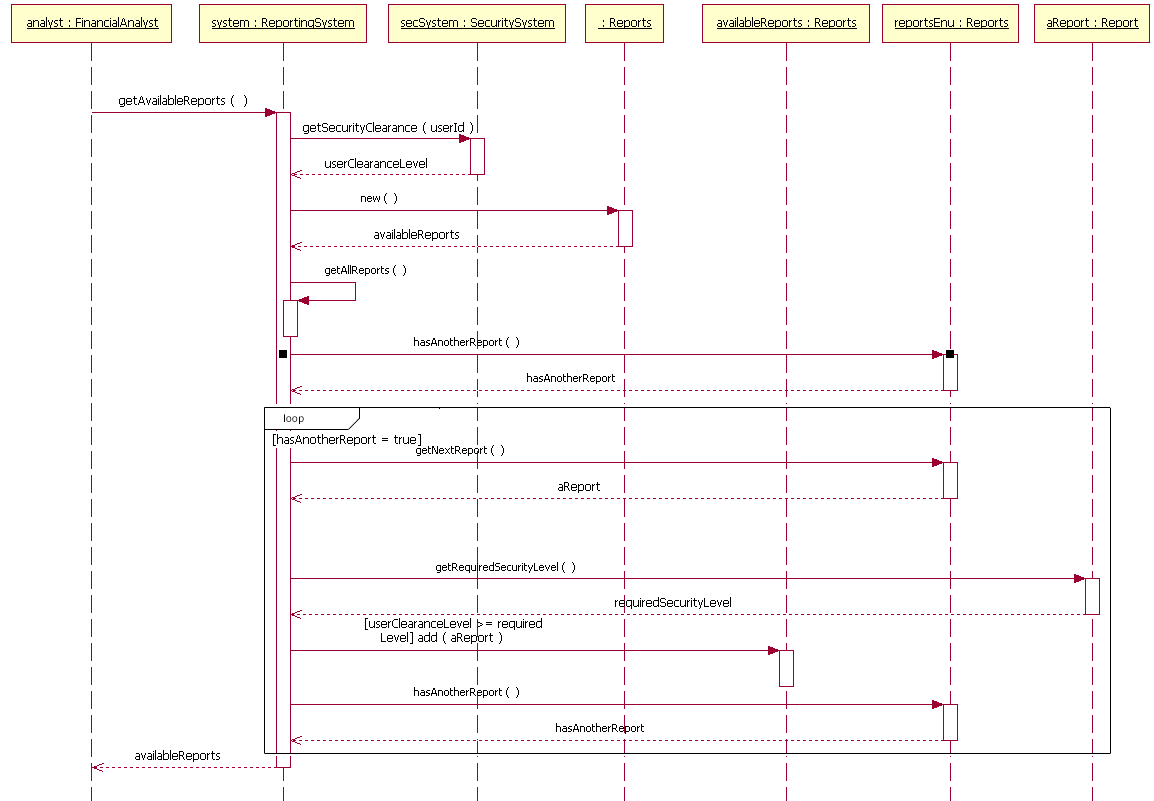
When indicating the flow of communication between objects, the part that controls the flow using conditions is called Guards. In the IBM document below, it is shown as “[pastDueBalance = 0].”
Combined Fragments
There are many conditions using in sequence diagram like below.
- Branches and Loops
- Concurrency and Order
- Filters and Assertions
- ignore
- consider
- assert
- neg
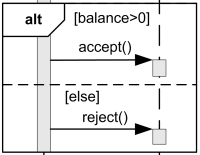
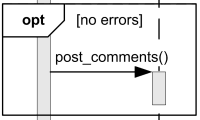
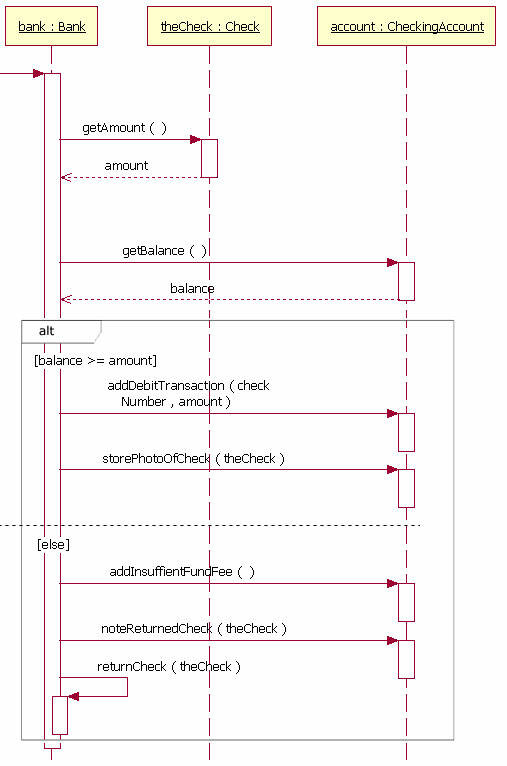
alt, opt
- alt: It can be thought of as a switch statement, allowing multiple conditions to control the flow.
- opt: It can be thought of as an if statement, where a specific condition controls the flow.
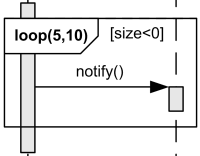
loop
- loop: It can control flow using loops based on conditions.
- Below shows iterate from 5 to 10 if “[size<0]” is true.
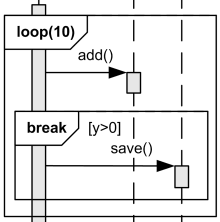
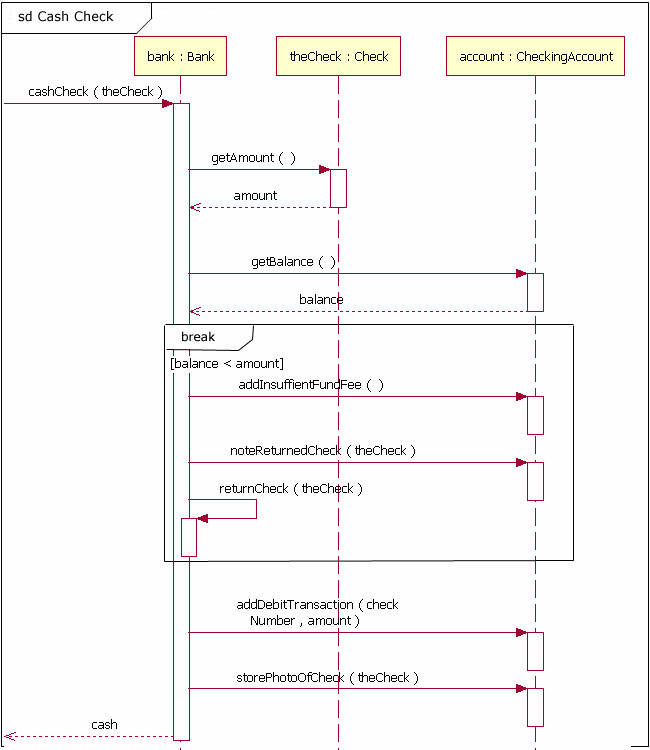
break
- break: It is like an exception in code. If condition met, it exits fragment even though there are rest things to do.
- If there were any additional contents below break fragment such as case below, they would not be executed and the loop would be exited.
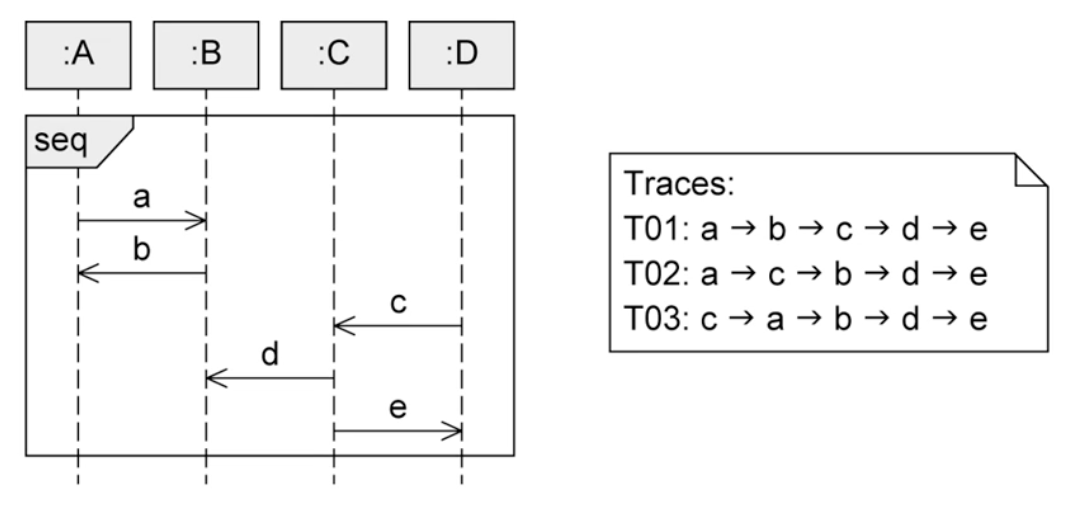
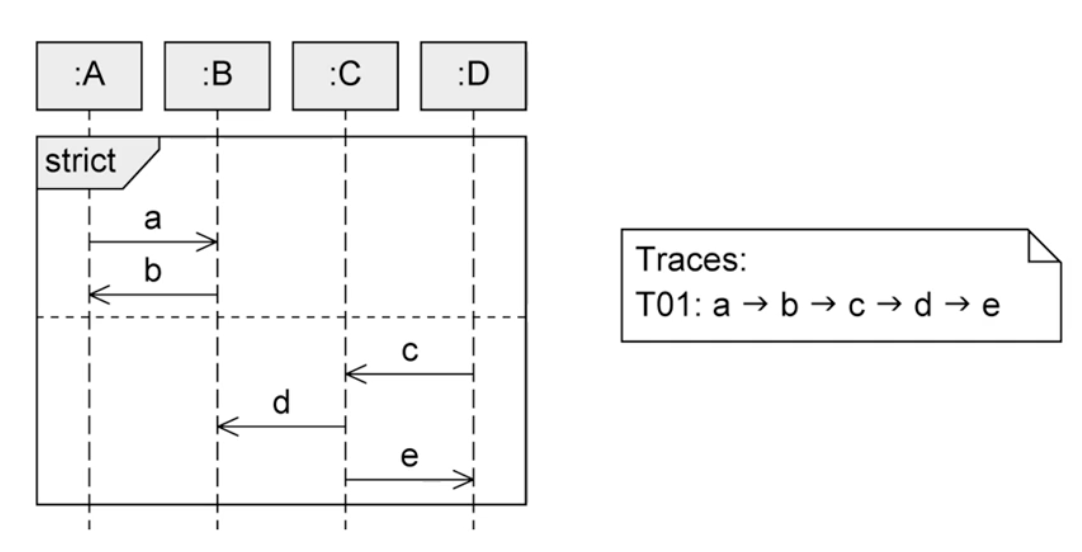
seq, strict
- seq: This is the default fragment, which can be considered as the basic sequence.
- strict: This fragment has a clear order where the parts divided by dotted lines must be executed sequentially.
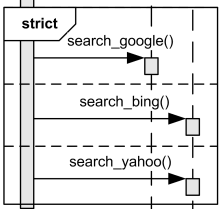
I found a good illustration on another blog that shows the difference between seq and strict. In the last diagram, the order is search_google() → search_bing() → search_yahoo().
par
- par: To represent something that can be performed in parallel as the term suggests.
- Each fragment divided by dotted lines can be executed independently without interference.
- In some documents, I’ve seen this referred to as concurrency rather than actual parallelism.
- In the diagram below, you can see that add() and remove() are requested in parallel.
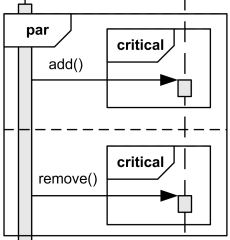
critical
- critical: It is an atomic area which interacts independently with prevent from interfering from others.
- The order within the critical fragment follows the default sequence.
- When entering the critical fragment, that flow runs firstly without other interrupt or other interactions.
- In the diagram below, add() and remove() can proceed in either order add()→remove() or remove()→add() but within the critical fragment, only one of them is executed before handling the next request.
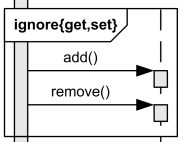
ignore
- ignore: It is used to ignore specific types of messages.
- The messages to be ignored are specified within the {} brackets.
- In the example below, the specified get and set messages are ignored.
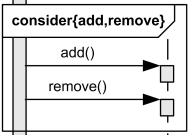
consider
- consider: It is used to highlight and emphasize specific types of messages while ignoring others.
- The messages to be highlighted or emphasized are specified within the {} brackets.
- In the example below, only add and remove are considered and the other messages are ignored.
assert
- assert: It is used to define parts of interactions that must always be true.
- Conditions are sometimes specified within {} brackets and these conditions must be satisfied.
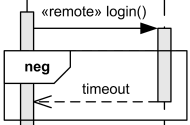
neg
- neg: It is used to represent cases that are invalid or have encountered an error.
- All parts that are not neg are assumed to be working normally.
- In the example below, a timeout indicates a case of failure.
Others
Reference
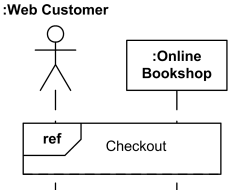
- It is an method which connects sequence diagrams. There is another sequence diagram exists in ref.
Reference